Porting KittenTTS to the Browser with OpenAI Codex
KittenTTS is a neat open-source
text-to-speech model that packs a surprising amount of punch in sizes as low as 25 MB. It
has over 11,000 stars on GitHub and for good reason — the output quality
is impressive for something you can run locally. The catch? It's Python-only,
needs pip install gymnastics, and you certainly can't just hand someone a link
and have them try it out.
The KittenTTS folks say they have browser version planned, but I was a bit impatient and also was eager to find out if a modern AI agent like Codex could pull off a Javascript port. The plan was simple: you open a page, pick a voice, type some text, and hear it speak. No server, no Python, no installs, available to client side web projects easily.
Spoiler alert: It actually worked almost single shot (I had to prompt my way through the plan and run a bunch of pnpm install commands to work around the sandbox basically). The results are up in https://github.com/jokkebk/KittenTTS-JS, but read on to find out how I got there with ChatGPT Codex 5.3 doing the heavy lifting.
The Plan
I started by asking Codex how hard it would be to create a browser JS port. It studied the Python codebase, identified the pipeline stages, and came back with a surprisingly thorough analysis. The core pipeline is:
- Text preprocessing (cleanup, sentence chunking)
- Phonemization via eSpeak
- Token mapping (phonemes to integer IDs)
- ONNX model inference per chunk
- Waveform concatenation
The model itself is a single ONNX graph that takes tokenized phonemes, a voice style vector, and a speed parameter, and outputs raw audio samples directly. No separate vocoder needed. This is key — it meant the browser port just needed ONNX Runtime Web and the right input pipeline.
Codex also noted the tricky bits: voice embeddings stored in NumPy's .npz
format (basically a ZIP of .npy files), and the eSpeak phonemizer which is a
C library. Both have WebAssembly ports available, making the whole thing
feasible. It laid out a 7-phase plan with API design, repo layout, risk
mitigations, and estimated about 7–8 days for a robust V1. I had it write
the plan to PLAN.md before proceeding — having that concrete reference
turned out to be valuable.
Letting Codex Work
With the plan saved, I told it to go ahead. Here's roughly what happened over the next few hours, based on the commit history:
13:37 — Bootstrap commit. Codex scaffolded a pnpm monorepo with a
@kittentts/web TypeScript package. The initial commit had 23 files and over
2,300 lines including:
- Model loader fetching artifacts from Hugging Face
- Full NPZ/NPY parser in TypeScript (supporting multiple NumPy dtypes)
- ONNX Runtime Web inference wrapper
- WAV encoder, audio playback helpers
- Tokenizer with the TextCleaner symbol map ported from Python
- Vitest test suite
13:48 — Input pipeline fixes. Text preprocessing got fleshed out with contraction expansion, decimal normalization, and proper sentence chunking.
14:52 — The big one. Browser demo with working eSpeak WASM phonemizer. This commit added the HTML demo page, CSS styling, and wired up the full pipeline: type text, pick a voice and speed, generate, play, download as WAV. The phonemizer loads eSpeak compiled to WebAssembly for proper English phoneme conversion, with a grapheme fallback if it fails.
Next morning — Polish. Licensing docs (Apache-2.0 for the JS code), and a bootstrap script that downloads model artifacts to local static assets so the demo can run without hitting Hugging Face at runtime.
Total: about 1,500 lines of TypeScript, a 180-line demo app, and a 300-line model bootstrap script. From zero to working browser TTS in an afternoon.
How It Works
The core API ended up clean:
const tts = await KittenTTSWeb.create({
modelRepo: "KittenML/kitten-tts-nano-0.8-int8",
executionProvider: "wasm",
phonemizerMode: "espeak"
});
const pcm = await tts.generate("Hello world!", {
voice: "Jasper",
speed: 1.0
});
playAudioPcm(pcm, 24_000);Under the hood, generate() chunks the text into sentences, runs each through
eSpeak WASM to get phonemes, maps those to token IDs, picks the right voice
style vector from the loaded embeddings, and feeds everything to the ONNX model.
The output chunks get concatenated (with some tail trimming to avoid artifacts)
into a single Float32Array of 24 kHz audio.
The NPZ parser was probably the most interesting piece — it's a full
runtime implementation of NumPy's binary format in TypeScript, handling variable
header sizes, multiple data types, and alignment edge cases. All so we can load
voice embeddings that the Python version reads with a one-liner np.load().
What Codex Got Right (and Wrong)
Codex nailed the structural port. The module decomposition, TypeScript types, ONNX Runtime integration, and even the NPZ binary format parsing were solid on first pass. The initial scaffold was genuinely impressive — 2,300 lines of reasonable code in one shot.
It was even able to iterate to match Python behavior in an exact manner. Text preprocessing edge cases, the precise token boundary markers ([0, ...ids, 10, 0]). On first run it sounded quite weird, so I asked about it and it gave me a bunch of possible reasons (missing punctuation and number support), but identifying the missing eSpeak WASM module (one of its hypotheses) was quite easy, and it pretty much steamrolled from that point onwards as well to a working demo.
I was quite impressed how Codex wrote its own plan first, and actually a bit flabbergasted when after a few "Can you start implementing this" / "Continue with the next phase" prompts I checked how far it had gone and realized there is a semi-working demo. :open_mouth:
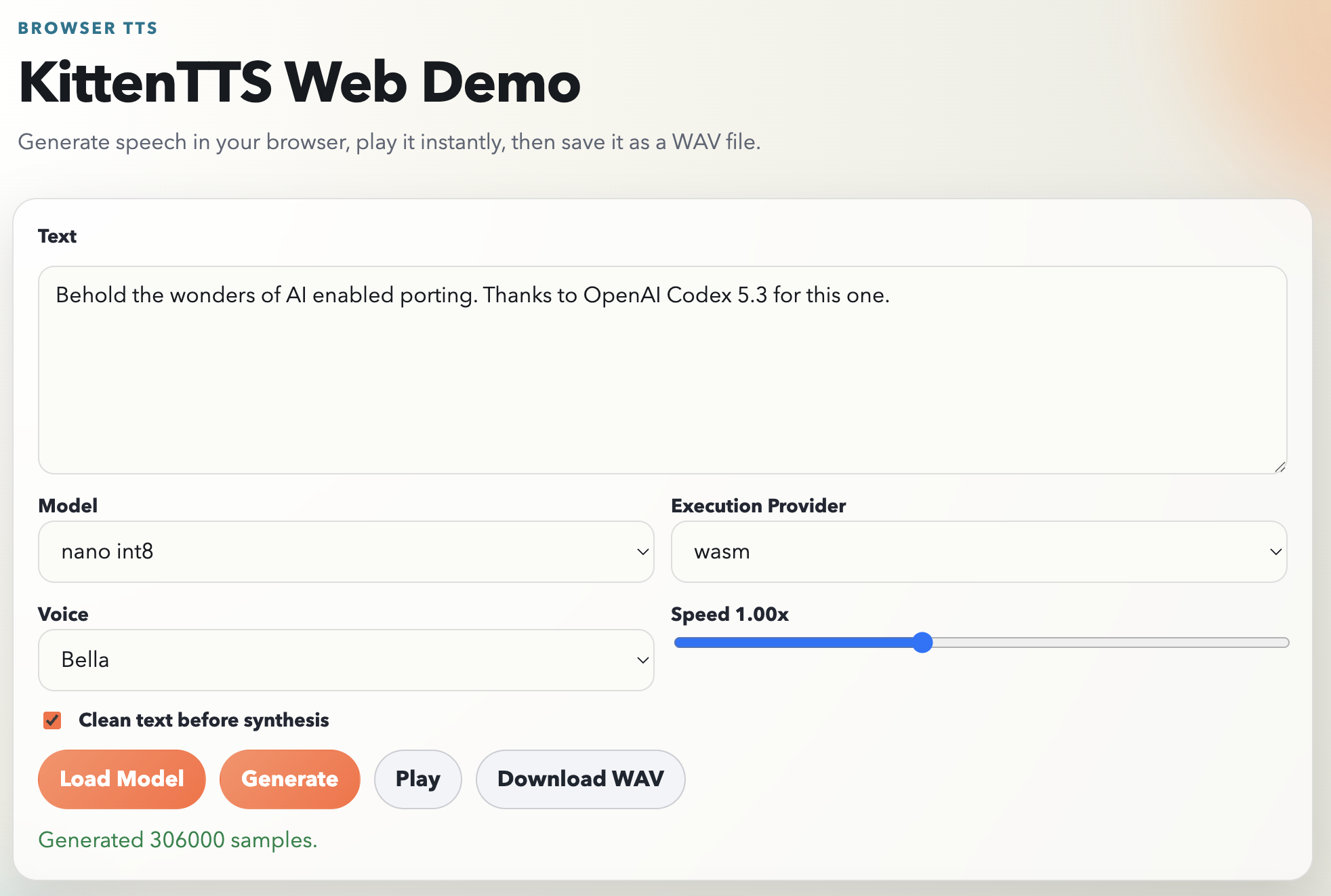
Try It Yourself
The project is at https://github.com/jokkebk/KittenTTS-JS. To run the demo locally:
git clone https://github.com/jokkebk/KittenTTS-JS
cd KittenTTS-JS
pnpm install
pnpm init:models
pnpm demoThen open http://localhost:5173/demo/index.html. Pick a voice (Bella, Jasper,
Luna and others), type something, and click Generate. Both int8 quantized and
fp32 models are supported, and you can switch between WASM and WebGPU execution
providers if your browser supports it.
The model download is about 25 MB on first load, cached by the browser after that. Generation takes a few seconds for a sentence on WASM — not instant but perfectly usable.
Notice: The port was done with OpenAI Codex 5.3. Codex analyzed the Python codebase, wrote the implementation plan, and produced the bulk of the code. I steered and did integration work. This blog post was drafted with Claude Code.